|
When I first encountered PICK databases, my biggest problem was how to get to the data. I was used to Microsoft products like Access and Excell and dreamed of marketing campaignes using Word and mail merge. But the data seemed so unreachably locked in a proprietary OS with only a terminal screen or printer as output.
A few months later I discovered WinLink and ViaODBC to connect my R83 system to mainstream applications. Finally the data were available for programming and mining. Visual Basic and the Winlink API really opened this world for me. I left ODBC for many years behind because of its (then) slow speed and the non-PICK syntax. But in April/May of 2000 I had the opportunity to set up ODBC for a large Universe application (MHC). I had some idea what needed to be done, I printed various manuals from the reference CD, and went to work. I was developing on Universe Linux 9.5.1.D The following is a "How-to", compiled from my personal experience, somebody else might see it different.
-
History of ODBC
- Setting up a PC for UniODBC
- A really great test and query tool
- Choosing a strategy
- Creating a new account
- Setting up this new account for ODBC
- Creating blank dictionaries for the files that you want to expose
- A conversion and copy tool
- A visual dictionary editor for UniVerse/Unidata
- HS.UPDATE.FILEINFO
- CREATE SCHEMA
- CREATE TABLE
- Permissions and privileges
You need to install the ODBC client software from the Universe Clients CD. Your system administrator should have this CD, it comes with the Universe system and every update.
When you insert the CD the autorun feature gives you the following screen:
If the install program doesn't start, run the setup.exe program on the CD.
Choose "UV/ODBC Client"
Go through the steps of the "Default" installation unless you want to be able to do diagnostic work. Then choose "Custom" and everything, including DrDeeBee spy, a very useful tool to sniff out ODBC protocol communication.
After you are done with the installation, you need to set up the connection that you want. Open the UVODBC configurator as in the picture below:
(Click to enlarge)
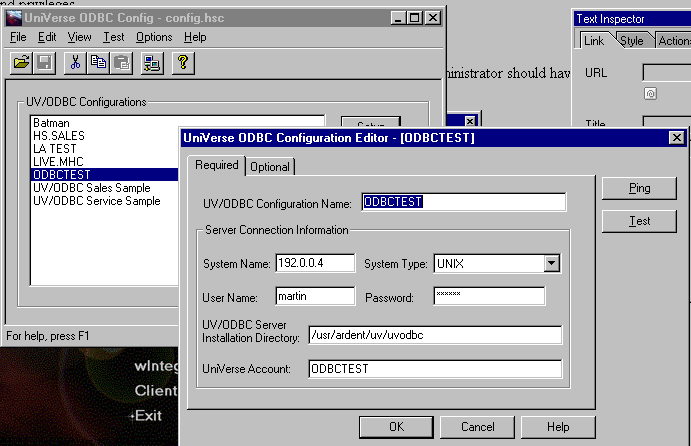
and define your data source just like int the next picture.
(Click to enlarge)
Test your configuration and you are there. If you encounter difficulties, check with your system administrator. One common problem is that your IP address must be in the hosts table on the server.
In the beginning I tested my work with Microsoft Access, but then I encountered problems. Access uses the JET data engine which has its own non standard ODBC rules. Sometimes you need to make a pass-through-query in order to get Access to work with Universe. I had to do an awful lot of pointing and clicking to get results. Then I discovered an ODBC Query tool at http:\\gpoulose.home.att.net. Download is free and the price is really modest, from 7 bucks for a single copy and $40 for 10.
Here a scren shot:
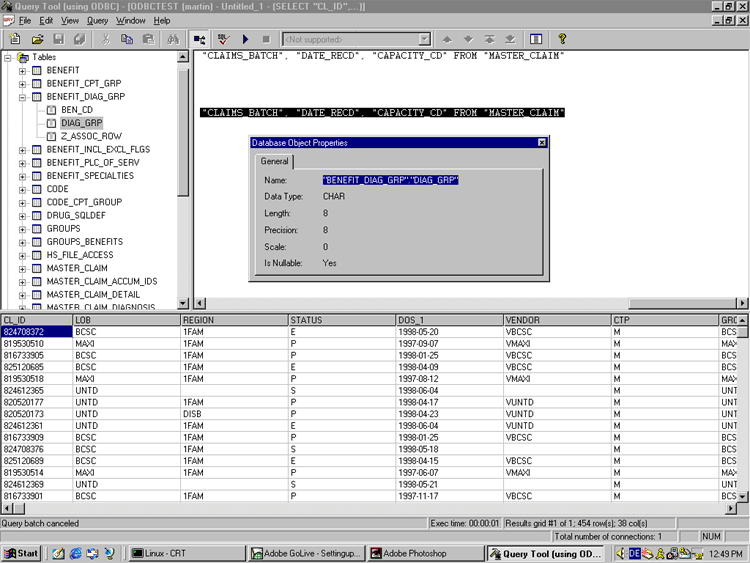 |
(Click to enlarge)
Now that the connectivity to the machine is established you have to carefully choose a strategy. I will just tell my particular story. I was faced with a 20 year old application. The dicitonaries are so full with junk attributes that nobody uses anymore. Also were most dictionary items in PICK style, that means A-type or S-type with often complicated T-correlations. T-Correlatives don't work at all times with UniODBC. Universe type dictionaries, the ones with 8 attributes instead of 10, work much better with ODBC. I chose to leave the old dictionaries alone and create a new one just for ODBC. You can off course modify the existing attributes but I did not want to take the risk of fouling up working set ups.
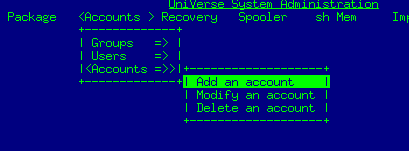
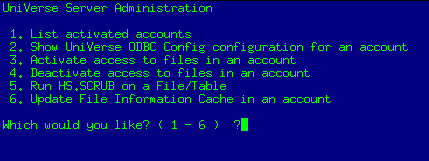
First I created a new account in Universe with the Administration tool
Log to the account HS.ADMIN and type "HS.ADMIN" and set this new account up for ODBC:
I logged to the new account and created new dictionaries for the all the files that i wanted exposed by using the TCL command "CREATE.FILE DICT filename 3 2 1"
Then I edited the VOC entry for the new file as
ED VOC MEMBERS
3 lines long.
----: P
0001: F
0002: /LIVE.MHC/MEMBERS
0003: D_MEMBERS
Bottom at line 3.
I used the new dictionary file but for the data section of the file I used the UNIX path of the data file in my Live system.
For information on how to edit the dictionaries, please check the chapter on the dictionary editor.
This is a command that update the hidden fileinfo file that controles the ODBC server. If you make any changes to the dictioaries for ODBC use, you have to issue this command. It updates a hidden file. Be sure you have the latest version of this program since Ardent improve a lot on the error messages since fall 1999.
Your files should be ready now.
|